|
Xingyu Zhou I am currently in my first year of pursuing a doctoral degree at University of Electronic Science and Technology of China (UESTC CVL-Lab). My advisor is Shuhang Gu. I received the B.S. degree from the Artificial Intelligence School, Xidian University in 2023. My previous research interest is low-level vision, such as image/video restoration, image enhancement and so on. My current research interest lies in image or video generation. However, what remains unchanged is that I have always been excited about how to build more efficient models, including training and inference. In addition, I believe that this will ultimately impact the development of the AI community. |

|
News[2026-02] Two papers IG and VE are accepted to CVPR 2026. [2026-01] One paper TVQ&RAP is accepted to ICLR 2026. [2025-06] One paper CTMSR is accepted to ICCV 2025. [2025-02] Two papers PFT-SR and DCAE are accepted to CVPR 2025. [2024-03] Three papers MIA-VSR, ATD-SR and FR-INR are accepted to CVPR 2024. |
Selected Publications |

|
Guiding a Diffusion Transformer with the Internal Dynamics of Itself
Xingyu Zhou, Qifan Li, Xiaobin Hu, Hai Chen, Shuhang Gu CVPR, 2026 (Highlight) project page / arXiv / code We achieve a new state of the art on ImageNet. IG delivers dramatic quality gains with far fewer training epochs, adds negligible overhead, and works as a drop-in upgrade for modern diffusion transformers. |
|
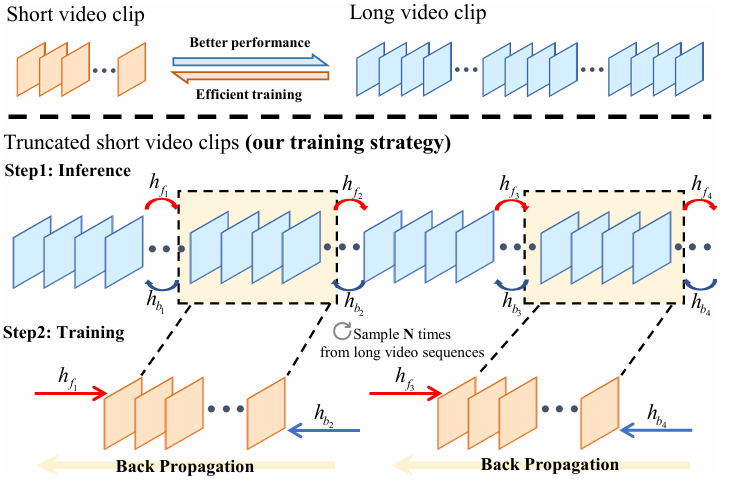
LRTI-VSR: Learning Long-Range Refocused Temporal Information for Video Super-Resolution
Xingyu Zhou, Wei Long, Jingbo Lu, Shiyin Jiang, Weiyi You, Haifeng Wu, Shuhang Gu arXiv, 2025 arXiv / code Investigate the ability of video super-resolution models to utilize long range temproal information. While enjoying the training efficiency of short video sequences, it achieves results equivalent to training on long video sequences. |
|
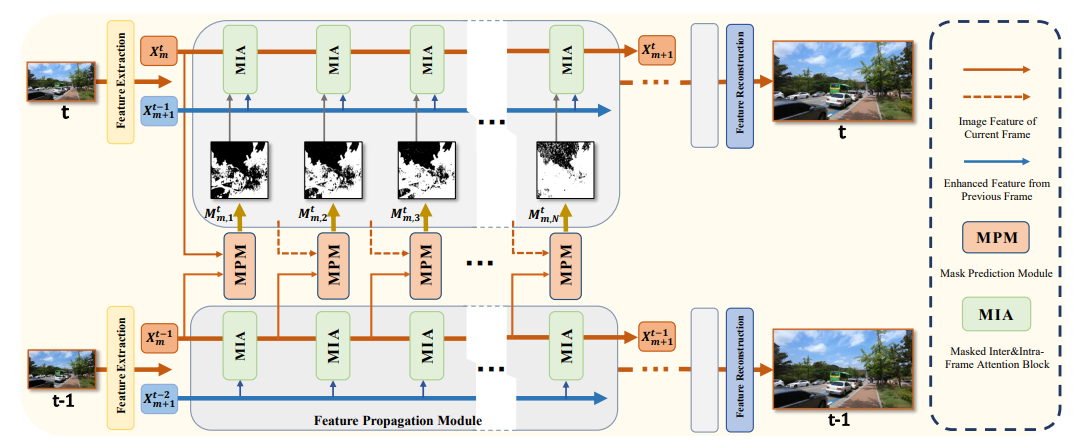
Video Super-Resolution Transformer with Masked Inter&Intra-Frame Attention
Xingyu Zhou Leheng Zhang, Xiaorui Zhao, Keze Wang, Leida Li, Shuhang Gu CVPR, 2024 arXiv / code Explore temporal redundancy in video super-resolution models. Achieve a significant reduction in the inference computational cost of video super-resolution models while not compromising restoration performance. |
|
Thank you to Jon Barron for the source code for the website! |